Notes blessed by the
goddess of knowledge.
Vīṇā turns lectures, meetings, PDFs and field notes into rich, subject-aware study material. Interactive widgets, real-time translation, and active learning that closes your gaps - not a one-size-fits-all summary.
- Amazing, comprehensive notes
- Targeted active learning
- Subject specific widgets
- Fine-tuned, not hallucinated
For an incompressible Newtonian fluid, conservation of momentum is expressed as ρ(∂v/∂t + v·∇v) = −∇p + μ∇²v + f. In steady, fully-developed laminar flow the inertial term vanishes…
/eq Reynolds number for 5 mm pipe, water at 20°C











Comprehensive notes you actually understand.
Prose, equations, diagrams, images, audio sync, code, field captures and live studio widgets - composed into one surface. Then bend that surface to how you think. Vīṇā adapts to you, not the other way around.
How a neural network actually learns.
Backpropagation is just credit assignment: the chain rule applied across a graph, asking each weight how much to blame.
∂L/∂wij = ∂L/∂yj · σ′(zj) · xi
Each weight learns from the local slope of its own contribution.
Three-layer perceptron - signals flow forward, gradients flow back.
Tap any line to hear what was said when you wrote it.
Drag to scrub through training epochs.
Click anything. The note above is real layout, not a screenshot - your choices flow through every Vīṇā note in your library.
Every class, every meeting, one dashboard.
Vīṇā plugs into Canvas, Brightspace, Blackboard, WebAssign - plus your email, Slack, and Teams - so subjects, deadlines and threads live together. Then it lets everything talk to one another through global chat.
Every way knowledge enters the room, vina listens in.
Six ways in, and every one of them routes to the same intelligent note surface.
Lectures, links, PDFs - anything.
Drop in lecture recordings, YouTube or Zoom links, slide decks, textbook PDFs, syllabi. Vīṇā structures it all into a subject-aware note with full citations back to the source.
Live recording with surgical precision.
Capture lectures in the room. We diarize speakers, flag definitions, surface whiteboard frames from your camera - no meeting bots, no permissions to beg for.
Meetings without bots in the room.
Zoom, Google Meet, Teams, Webex - Vīṇā observes from your side only. No one sees 'Vīṇā has joined.' No IT tickets. Just clean notes after.
Your handwriting, understood.
Snap a photo of your page - or link your tablet. We OCR, parse your diagrams, and layer them into the studio note as first-class, interactive artefacts.
Real-time translation HUD.
Sit in a lecture in any language, read it in yours. Terms of art, named entities and equations stay intact - we don't paraphrase what matters.
Every paper, clipped and sourced.
Highlight any passage on an arXiv paper, Wikipedia, a blog, or a course site. Vīṇā clips it, keeps the citation, and folds it straight into your active note.
Works where you already live.
Canvas, Brightspace, Blackboard, WebAssign, Zoom, Google Meet, Teams, Webex, Slack, Google Drive, Notion, Outlook, Gmail. Vīṇā sits at the centre and pulls every fragmented platform into one cohesive workspace.

 Canvas
Canvas Brightspace
Brightspace Slack
Slack Zoom
ZoomNo one-size-fits-all. Water flows to the right shape.
Every subject gets its own interactive widgets. Tap one on the right - the notes on the left re-tune themselves, instantly.
SN2 proceeds through a single concerted step with a back-side attack, leading to inversion of configuration. SN1 proceeds through a carbocation intermediate and gives a mixture of stereochemistries.
Source: Clayden, Organic Chemistry, 2nd ed. · p. 332
Tap one - Vīṇā re-threads the note around it, instantly.
Flip between a structured, widget-rich summary and the raw word of your lecturer. Click any line and jump the audio straight to it.
Your handwritten notes, corrected, completed, alive.
Drop your field notes in. Vīṇā compares them to the lecture, shows you what you missed, what you got wrong, and where to pay attention next time. No one else does this.
3 gaps, 2 misconceptions, 1 beautifully-drawn diagram.
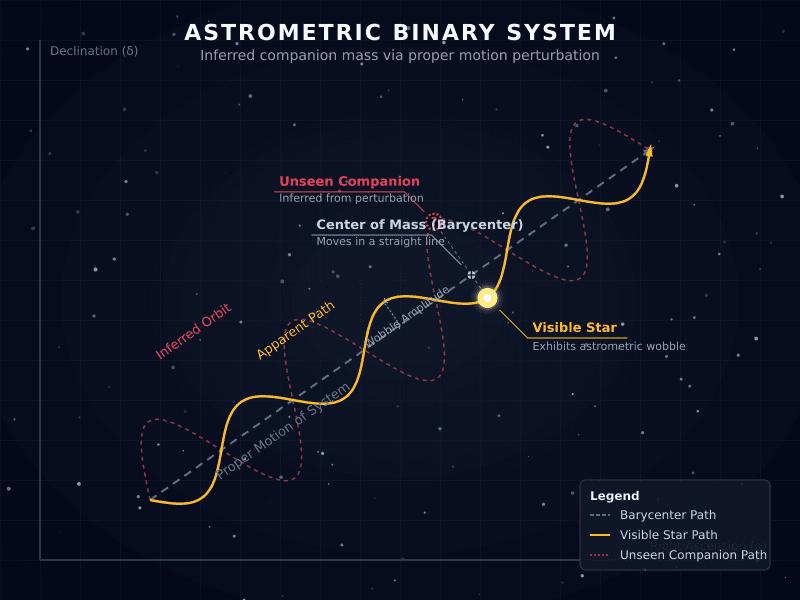
v(R) = 0. Added to your notes with a timestamp link.Generate and receive accurate academic images with Vina's Proprietary Image System M. Tangi 1.0
Built for complex academic and technical visuals, M.Tangi 1.0 generates images that are readable, structured, accurately labelled and actually useful for learning, not just visually impressive.
Designed for diagrams, equations, labels, multilingual scripts, technical explanations, and classroom-ready visuals.
import torch, torch.nn.functional as F
from tangi.unet import UNet2DConditioned
from tangi.vae import AutoencoderKL
from tangi.clip import CLIPTextEncoder
from tangi.scheduler import DDPMScheduler
enc = CLIPTextEncoder("tangi-clip-L14")
unet = UNet2DConditioned.from_pretrained(
"m-tangi-v1", torch_dtype=torch.fp16,
cross_attn_dim=768, layers=24,
attn_heads=12, ff_mult=4,
).to("cuda")
vae = AutoencoderKL(latent_ch=4, scale=0.18215)
sched = DDPMScheduler(steps=50, beta=(1e-4,0.02))
tok = enc.tokenize("astrometric binary, labeled")
cond = enc(tok).last_hidden_state
latent = torch.randn(1,4,96,72, device="cuda")
for i, t in enumerate(sched.timesteps):
with torch.cuda.amp.autocast():
noise_pred = unet(latent, t, cond).sample
latent = sched.step(noise_pred, t, latent)
x = vae.decode(latent / vae.config.scale_factor)
img = ((x.clamp(-1,1)+1)/2*255).byte()
save_png(img, "diagram.png", dpi=300)class CrossAttentionBlock(nn.Module):
def __init__(self, dim, ctx_dim, heads=8):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(dim, heads)
self.cross = nn.MultiheadAttention(dim, heads)
self.ff = nn.Sequential(
nn.Linear(dim, dim*4), nn.GELU(),
nn.Dropout(0.1), nn.Linear(dim*4, dim))
self.proj_ctx = nn.Linear(ctx_dim, dim)
def forward(self, x, ctx, t_emb):
h = self.norm1(x + t_emb.unsqueeze(1))
h = self.attn(h, h, h)[0] + x
ctx_proj = self.proj_ctx(ctx)
h = self.cross(h, ctx_proj, ctx_proj)[0] + h
h = self.ff(self.norm2(h)) + h
scale = torch.sigmoid(self.gate(t_emb))
return h * scale.unsqueeze(1)
def _init_weights(self):
nn.init.zeros_(self.gate.weight)
nn.init.zeros_(self.ff[-1].weight)
nn.init.xavier_uniform_(self.proj_ctx.weight)class LabelPlacementEngine:
def __init__(self, vocab, font_cfg, collision_r=8):
self.detector = EntityDetector(vocab, thr=0.72)
self.font = FontRasterizer(**font_cfg)
self.col_r = collision_r
self.grid = SpatialHashGrid(cell=16)
def place(self, feature_map, layout):
entities = self.detector(feature_map)
anchors = self._compute_anchors(entities)
placed, rejected = [], []
for ent, anchor in zip(entities, anchors):
bbox = self.font.measure(ent.text, ent.size)
candidates = self._radial_candidates(
anchor, bbox, steps=24, max_r=60)
best = None
for c in candidates:
if not self.grid.collides(c, self.col_r):
score = self._score(c, anchor, layout)
if best is None or score > best[1]:
best = (c, score)
if best:
self.grid.insert(best[0])
leader = self._cubic_leader(anchor, best[0])
placed.append(Label(ent, best[0], leader))
else: rejected.append(ent)
return placed, rejecteddef ddpm_sample(unet, sched, cond, cfg_scale=7.5):
b, device = cond.shape[0], cond.device
x = torch.randn(b, 4, 96, 72, device=device)
uncond = torch.zeros_like(cond)
for i, t in enumerate(sched.timesteps):
t_batch = t.expand(b).to(device)
x_in = torch.cat([x, x], dim=0)
c_in = torch.cat([uncond, cond], dim=0)
with torch.no_grad():
eps = unet(x_in, t_batch.repeat(2), c_in)
eps_u, eps_c = eps.chunk(2)
eps = eps_u + cfg_scale * (eps_c - eps_u)
alpha_t = sched.alphas_cumprod[t]
alpha_prev = sched.alphas_cumprod[t - 1]
sigma = ((1-alpha_prev)/(1-alpha_t)*(1-alpha_t/alpha_prev)).sqrt()
pred_x0 = (x - (1-alpha_t).sqrt()*eps) / alpha_t.sqrt()
pred_x0 = pred_x0.clamp(-1, 1)
dir_xt = (1 - alpha_prev - sigma**2).sqrt() * eps
noise = sigma * torch.randn_like(x) if t > 1 else 0
x = alpha_prev.sqrt()*pred_x0 + dir_xt + noise
if i % 10 == 0:
yield x, t.item()
return xclass VAEDecoder(nn.Module):
def __init__(self, ch=128, z_ch=4, out_ch=3):
super().__init__()
self.conv_in = nn.Conv2d(z_ch, ch*8, 3, pad=1)
self.mid = nn.Sequential(
ResBlock(ch*8, ch*8), AttnBlock(ch*8),
ResBlock(ch*8, ch*8))
self.up = nn.ModuleList([
UpBlock(ch*8, ch*8, upsample=True),
UpBlock(ch*8, ch*4, upsample=True),
UpBlock(ch*4, ch*2, upsample=True),
UpBlock(ch*2, ch, upsample=True)])
self.norm_out = nn.GroupNorm(32, ch)
self.conv_out = nn.Conv2d(ch, out_ch, 3, pad=1)
def forward(self, z):
h = self.conv_in(z)
h = self.mid(h)
for block in self.up:
h = block(h)
h = F.silu(self.norm_out(h))
return torch.tanh(self.conv_out(h))
@torch.inference_mode()
def decode_latent(self, z, scale=0.18215):
z = z / scale
img = self.forward(z)
return ((img + 1) / 2 * 255).clamp(0, 255).byte()import torch, torch.nn.functional as F
from tangi.unet import UNet2DConditioned
from tangi.vae import AutoencoderKL
from tangi.clip import CLIPTextEncoder
from tangi.scheduler import DDPMScheduler
enc = CLIPTextEncoder("tangi-clip-L14")
unet = UNet2DConditioned.from_pretrained(
"m-tangi-v1", torch_dtype=torch.fp16,
cross_attn_dim=768, layers=24,
attn_heads=12, ff_mult=4,
).to("cuda")
vae = AutoencoderKL(latent_ch=4, scale=0.18215)
sched = DDPMScheduler(steps=50, beta=(1e-4,0.02))
tok = enc.tokenize("astrometric binary, labeled")
cond = enc(tok).last_hidden_state
latent = torch.randn(1,4,96,72, device="cuda")
for i, t in enumerate(sched.timesteps):
with torch.cuda.amp.autocast():
noise_pred = unet(latent, t, cond).sample
latent = sched.step(noise_pred, t, latent)
x = vae.decode(latent / vae.config.scale_factor)
img = ((x.clamp(-1,1)+1)/2*255).byte()
save_png(img, "diagram.png", dpi=300)class CrossAttentionBlock(nn.Module):
def __init__(self, dim, ctx_dim, heads=8):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(dim, heads)
self.cross = nn.MultiheadAttention(dim, heads)
self.ff = nn.Sequential(
nn.Linear(dim, dim*4), nn.GELU(),
nn.Dropout(0.1), nn.Linear(dim*4, dim))
self.proj_ctx = nn.Linear(ctx_dim, dim)
def forward(self, x, ctx, t_emb):
h = self.norm1(x + t_emb.unsqueeze(1))
h = self.attn(h, h, h)[0] + x
ctx_proj = self.proj_ctx(ctx)
h = self.cross(h, ctx_proj, ctx_proj)[0] + h
h = self.ff(self.norm2(h)) + h
scale = torch.sigmoid(self.gate(t_emb))
return h * scale.unsqueeze(1)
def _init_weights(self):
nn.init.zeros_(self.gate.weight)
nn.init.zeros_(self.ff[-1].weight)
nn.init.xavier_uniform_(self.proj_ctx.weight)class LabelPlacementEngine:
def __init__(self, vocab, font_cfg, collision_r=8):
self.detector = EntityDetector(vocab, thr=0.72)
self.font = FontRasterizer(**font_cfg)
self.col_r = collision_r
self.grid = SpatialHashGrid(cell=16)
def place(self, feature_map, layout):
entities = self.detector(feature_map)
anchors = self._compute_anchors(entities)
placed, rejected = [], []
for ent, anchor in zip(entities, anchors):
bbox = self.font.measure(ent.text, ent.size)
candidates = self._radial_candidates(
anchor, bbox, steps=24, max_r=60)
best = None
for c in candidates:
if not self.grid.collides(c, self.col_r):
score = self._score(c, anchor, layout)
if best is None or score > best[1]:
best = (c, score)
if best:
self.grid.insert(best[0])
leader = self._cubic_leader(anchor, best[0])
placed.append(Label(ent, best[0], leader))
else: rejected.append(ent)
return placed, rejecteddef ddpm_sample(unet, sched, cond, cfg_scale=7.5):
b, device = cond.shape[0], cond.device
x = torch.randn(b, 4, 96, 72, device=device)
uncond = torch.zeros_like(cond)
for i, t in enumerate(sched.timesteps):
t_batch = t.expand(b).to(device)
x_in = torch.cat([x, x], dim=0)
c_in = torch.cat([uncond, cond], dim=0)
with torch.no_grad():
eps = unet(x_in, t_batch.repeat(2), c_in)
eps_u, eps_c = eps.chunk(2)
eps = eps_u + cfg_scale * (eps_c - eps_u)
alpha_t = sched.alphas_cumprod[t]
alpha_prev = sched.alphas_cumprod[t - 1]
sigma = ((1-alpha_prev)/(1-alpha_t)*(1-alpha_t/alpha_prev)).sqrt()
pred_x0 = (x - (1-alpha_t).sqrt()*eps) / alpha_t.sqrt()
pred_x0 = pred_x0.clamp(-1, 1)
dir_xt = (1 - alpha_prev - sigma**2).sqrt() * eps
noise = sigma * torch.randn_like(x) if t > 1 else 0
x = alpha_prev.sqrt()*pred_x0 + dir_xt + noise
if i % 10 == 0:
yield x, t.item()
return xclass VAEDecoder(nn.Module):
def __init__(self, ch=128, z_ch=4, out_ch=3):
super().__init__()
self.conv_in = nn.Conv2d(z_ch, ch*8, 3, pad=1)
self.mid = nn.Sequential(
ResBlock(ch*8, ch*8), AttnBlock(ch*8),
ResBlock(ch*8, ch*8))
self.up = nn.ModuleList([
UpBlock(ch*8, ch*8, upsample=True),
UpBlock(ch*8, ch*4, upsample=True),
UpBlock(ch*4, ch*2, upsample=True),
UpBlock(ch*2, ch, upsample=True)])
self.norm_out = nn.GroupNorm(32, ch)
self.conv_out = nn.Conv2d(ch, out_ch, 3, pad=1)
def forward(self, z):
h = self.conv_in(z)
h = self.mid(h)
for block in self.up:
h = block(h)
h = F.silu(self.norm_out(h))
return torch.tanh(self.conv_out(h))
@torch.inference_mode()
def decode_latent(self, z, scale=0.18215):
z = z / scale
img = self.forward(z)
return ((img + 1) / 2 * 255).clamp(0, 255).byte()
Type like you think. / commands do the rest.
Vīṇā reads your intent. Drop in an equation in English, ask for a real image, spin up an interactive widget, or ask it to go deeper - all without leaving the page.
SN2 proceeds through a concerted back-side attack. The key stereochemical consequence is inversion of configuration.
…and just like that, it's in the note, interactive, and linked back to the lecture timestamp.
A tutor, not a cheat sheet. You pick the mode.
Vīṇā defaults to helping you learn - asks leading questions, surfaces your weak spots, cites back to lecture moments. Switch to Answer mode when you need it.
Ask across a single note, a whole subject, or every note in your workspace.
One note. A studio of twelve tools.
Every note becomes an entire study arsenal. Audio, video, flashcards, a deck, a mind map, a debate - generated on demand from the same source of truth.
The fastest way to learn something is to teach it back.
Vīṇā plays the curious student. You lecture. It interrupts with real questions - the kind you'd hate to get wrong. At the end you get a comprehension score, pinpointed to the exact minute of confusion.
Themed notes that actually work.
Theming isn't a palette swap. The voice, the framing, even the chapter title change to fit the mood you chose - but the equations, figures and numerical values stay bit-for-bit identical. Rigor preserved. Feel dialed.
For an incompressible Newtonian fluid, conservation of momentum givesρ(∂v/∂t + v·∇v) = −∇p + μ∇²v + f. In steady laminar flow the inertial term vanishes - the Poiseuille solution falls out directly. The Reynolds number Re = ρvL/μ sets the transition regime; above Re ≈ 2300 disturbances begin to grow nonlinearly.
Same equations, same numbers, every theme. Only the mood changes.
For meetings you run, not ones you sat through.
Virtual or in-person. Vīṇā joins nothing, observes everything. Temperature analysis, attendee identification, interactive decision & task ledgers - and a bridge that sets up your next one.
Audio, transcript and notes - in perfect step.
Scrub the audio. The transcript highlights word-by-word. The studio note scrolls to the exact chunk. Click any word, any paragraph, any diagram and jump straight to the moment.
For steady, fully-developed laminar flow in a circular pipe, the velocity profile is parabolic.
At the wall, viscous no-slip enforces v(R) = 0; at the centre, v attains its maximum.
Reynolds number compares inertial to viscous forces and governs the onset of turbulence.
Three days out. Arm the lockdown.
One flip of the switch. Vīṇā drops every non-essential tool, surfaces only quiz + study guide, and locks you into the exact weak spots you've been avoiding.
Wander through a podcast version of chapter 7, build a mind map of the reward pathway, or let the AI become your student and see what you actually understand.
Try the switch. Arm it. Disarm it. This is how it feels three days before your midterm.
Think together. In perfect time.
Live cursors, shared highlights, inline comments, and presence. Vīṇā lets a whole research group, study cohort, or editorial desk move as one instrument.
The raga unfolds not as a melody but as a field - an atmosphere the musician inhabits rather than performs.
Each ornamentation is both deliberate and discovered, a conversation between intention and breath.
In this sense, attention itself becomes the instrument - and the listener, a second player whose presence shapes the sound as much as any string.
Plays well with everything.
Vīṇā reaches into the tools you already use, pulls context in, and stays in sync. One-way, two-way, or archive-only - you decide.
Notes blessed by Mata Saraswati.
Vīṇā takes the noise of lectures, readings and half-finished thoughts, and tunes them into something that actually stays with you. Random knowledge becomes melodious knowledge - ordered, resonant, lasting - the way the tunes of the vīṇā linger in the air long after the string is still.
A mind that plays
itself back.
Stop collecting thoughts. Start composing with them. Vīṇā is the second brain that remembers, rehearses, and resonates - a single instrument for everything you think.